ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35
ID Name Age
0 4 David 40
1 5 Eve 50
2 6 Frank 60
ID Name Age
Group 1 0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35
Group 2 0 4 David 40
1 5 Eve 50
2 6 Frank 60
DataFrame 1:
ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35
3 4 David 40
DataFrame 2:
ID Department Salary
0 3 HR 50000
1 4 Finance 60000
2 5 IT 70000
3 6 Marketing 80000
Outer Join Result:
ID Name Age Department Salary
0 1 Alice 25.0 NaN NaN
1 2 Bob 30.0 NaN NaN
2 3 Charlie 35.0 HR 50000.0
3 4 David 40.0 Finance 60000.0
4 5 NaN NaN IT 70000.0
5 6 NaN NaN Marketing 80000.0
Right Join Result:
ID Name Age Department Salary
0 3 Charlie 35.0 HR 50000
1 4 David 40.0 Finance 60000
2 5 NaN NaN IT 70000
3 6 NaN NaN Marketing 80000
ID Name Age
0 1 Alice 25
1 2 Bob 30
2 3 Charlie 35
3 4 David 40
Salary
1 50000
2 60000
3 70000
ID Name Age Salary
0 1 Alice 25 NaN
1 2 Bob 30 50000.0
2 3 Charlie 35 60000.0
3 4 David 40 70000.0
ID Name Age Salary
1 2 Bob 30 50000
2 3 Charlie 35 60000
3 4 David 40 70000
ID Name Age Salary
0 1 Alice 25 NaN
1 2 Bob 30 50000.0
2 3 Charlie 35 60000.0
3 4 David 40 70000.0
Append - Հնացած ա, նույնն ա ինչ ուղղակի տողերի concat-ը
result = df1.append(df2)print(result)result = pd.concat([df1, df2], axis=0)print(result)
---------------------------------------------------------------------------AttributeError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_32508\1643112403.py in ?()----> 1result = df1.append(df2) 2 print(result) 3 4 result = pd.concat([df1, df2], axis=0)c:\Users\hayk_\.conda\envs\lectures\lib\site-packages\pandas\core\generic.py in ?(self, name) 6314and name notin self._accessors
6315and self._info_axis._can_hold_identifiers_and_holds_name(name) 6316 ):
6317return self[name]-> 6318return object.__getattribute__(self, name)AttributeError: 'DataFrame' object has no attribute 'append'
Երբ որը օգտագործել
concat() - հասարակ տողեր/սյուներ ավելանցելու համար
merge() - ըստ ընդհանուր սյուների միավորումներ անելու համար
join() - ինդեքսով միավորելու, կամ merge գրել ալարելու դեպքում
Միշտ հիշեք ստուգել NA (Not available)-ներ առաջացել են թե չէ միավորումից հետո
Excel
!pip install uv
!uv pip install openpyxl
Using Python 3.10.18 environment at: C:\Users\hayk_\.conda\envs\lectures
Resolved 2 packages in 1.38s
Prepared 2 packages in 1.70s
Installed 2 packages in 277ms
+et-xmlfile==2.0.0
+openpyxl==3.1.5
Արհեստական տվյալների ստեղծում
import pandas as pdimport numpy as npfrom datetime import datetime, timedelta# Create a date range for one year of trading data (252 days)date_range = pd.date_range(end=datetime.today(), periods=252, freq='B')# Generate synthetic stock data for two different stocksstock1 = pd.DataFrame({'date': date_range,'price': (np.random.rand(252) +0.5).cumprod() *100,'volume': np.random.randint(1000, 10000, 252)}).set_index('date')stock2 = pd.DataFrame({'date': date_range,'price': (np.random.rand(252) +0.5).cumprod() *200,'volume': np.random.randint(1000, 10000, 252)}).set_index('date')# Create a Pandas Excel writer using XlsxWriter as the enginewith pd.ExcelWriter('financial_data.xlsx', engine='openpyxl') as writer:# Write each DataFrame to a different worksheet stock1.to_excel(writer, sheet_name='Stock1') stock2.to_excel(writer, sheet_name='Stock2')
df = pd.read_excel('financial_data.xlsx') # կարդումա առաջին sheetըdf
date
price
volume
0
2024-07-23 18:27:46.268
83.291510
7344
1
2024-07-24 18:27:46.268
103.498104
6112
2
2024-07-25 18:27:46.268
140.786008
2383
3
2024-07-26 18:27:46.268
92.593919
3448
4
2024-07-29 18:27:46.268
47.409393
5555
...
...
...
...
247
2025-07-03 18:27:46.268
0.002276
7439
248
2025-07-04 18:27:46.268
0.001610
8411
249
2025-07-07 18:27:46.268
0.001547
3468
250
2025-07-08 18:27:46.268
0.002221
8436
251
2025-07-09 18:27:46.268
0.002448
3467
252 rows × 3 columns
# Reading a specific sheet by its namedf = pd.read_excel('financial_data.xlsx', sheet_name='Stock2')print(df.head())# Reading a specific sheet by its indexdf = pd.read_excel('financial_data.xlsx', sheet_name=1)print(df.head())
# Reading a subset of columns by their namesdf = pd.read_excel('financial_data.xlsx', usecols=['price', 'volume'])print(df.head(1))# Reading a subset of columns by Excel column lettersdf = pd.read_excel('financial_data.xlsx', usecols='B,C')print(df.head(1))
նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_men
բացարձակ արժեք_women
նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_women
0
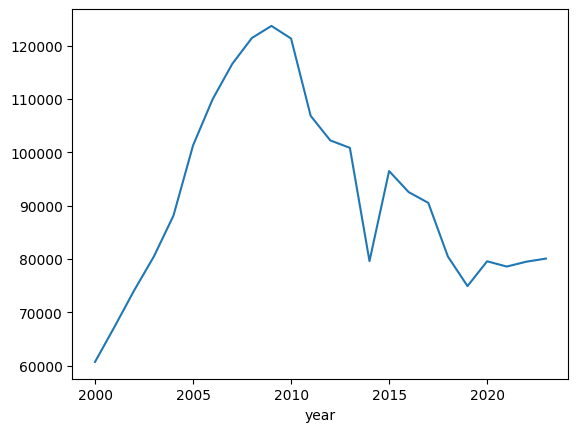
2000
27401.0
96.6
33325.0
99.8
1
2001
30320.0
110.7
37026.0
111.1
2
2002
34087.0
112.4
40067.0
108.2
3
2003
35694.0
104.7
44780.0
111.8
4
2004
38961.0
109.2
49178.0
109.8
5
2005
45661.0
117.2
55640.0
113.1
6
2006
49427.0
108.2
60549.0
108.8
7
2007
52489.0
106.2
64099.0
105.9
8
2008
55826.0
106.4
65618.0
102.4
9
2009
56533.0
101.3
67177.0
102.4
10
2010
55669.0
98.5
65678.0
97.8
11
2011
48176.0
86.5
58679.0
89.3
12
2012
47004.0
97.6
55246.0
94.1
13
2013
45810.0
97.5
55044.0
99.6
14
2014
38044.0
93.9
41579.0
92.8
15
2015
42901.0
99.8
53601.0
104.9
16
2016
42095.0
98.1
50463.0
94.1
17
2017
41213.0
97.9
49327.0
97.7
18
2018
37087.0
90.0
43390.0
88.0
19
2019
33456.0
90.2
41486.0
95.6
20
2020
35403.0
105.8
44187.0
106.5
21
2021
47432.0
134.0
31171.0
70.5
22
2022
34140.0
72.0
45373.0
145.6
23
2023
33367.0
97.7
46728.0
103.0
df.columns
Index(['թվական', 'բացարձակ արժեք_men',
'նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_men',
'բացարձակ արժեք_women',
'նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_women'],
dtype='object')
df.drop(columns=['նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_men','նախորդ տարվա համապատասխան ժամանակաշրջանի նկատմամբ (%)_women'], inplace=True)
students
year gender
2000 men 27401.0
women 33325.0
2001 women 37026.0
men 30320.0
2002 men 34087.0
women 40067.0
2003 women 44780.0
men 35694.0
2004 men 38961.0
women 49178.0
2005 women 55640.0
men 45661.0
2006 men 49427.0
women 60549.0
2007 women 64099.0
men 52489.0
2008 men 55826.0
women 65618.0
2009 women 67177.0
men 56533.0
2010 men 55669.0
women 65678.0
2011 women 58679.0
men 48176.0
2012 men 47004.0
women 55246.0
2013 women 55044.0
men 45810.0
2014 men 38044.0
women 41579.0
2015 women 53601.0
men 42901.0
2016 women 50463.0
men 42095.0
2017 men 41213.0
women 49327.0
2018 women 43390.0
men 37087.0
2019 men 33456.0
women 41486.0
2020 women 44187.0
men 35403.0
2021 men 47432.0
women 31171.0
2022 women 45373.0
men 34140.0
2023 men 33367.0
women 46728.0
C:\Users\hayk_\AppData\Local\Temp\ipykernel_32508\50020301.py:1: UserWarning: Could not infer format, so each element will be parsed individually, falling back to `dateutil`. To ensure parsing is consistent and as-expected, please specify a format.
msft["Date"] = pd.to_datetime(msft["Date"]) # parse strings → Timestamp
C:\Users\hayk_\AppData\Local\Temp\ipykernel_32508\2846096206.py:1: FutureWarning: 'M' is deprecated and will be removed in a future version, please use 'ME' instead.
monthly = msft["Close"].resample("M").mean()
 Կարմիրքար (Մեծն Փառախադեմ)
Կարմիրքար (Մեծն Փառախադեմ)