import os
assert os.getenv("OPENAI_API_KEY"), \
"Please set the OPEAI_API_KEY environment variable with your OpenAI API key."01 OpenAI + Timestamp
 “Yerevan basement, dates back 200 years. There are canvases in the basement now. It’s an art place.” լուսանկարի հղումը, Հեղինակ՝ Ashkhen Gevorgyan
“Yerevan basement, dates back 200 years. There are canvases in the basement now. It’s an art place.” լուսանկարի հղումը, Հեղինակ՝ Ashkhen Gevorgyan
![]() (ToDo)
(ToDo)
📌 Նկարագիր
OpenAI-ը ChatGPT-ն ստեղծող կամպանյան ա։ էսօր սովորելու ենք թե ինչ բան ա API-ը ու ոնց կարանք request-ներ անենք (էս թեմային մի քիչ առնչվել ենք deepl-ով թարմանություններ անելիս): Նաև սովորում ենք environment variable-ների գաղափարը (տերմինալի հրամանակ աշխատացնելով ենք անում դասի ժամանակ, ավելի լավ ա dotenv-ով անել, տես վիդեոն)։
OpenAI-ով նայում ենք թե ոնց ա կարելի տեքստեր/նկարներ/աուդիո գեներացնել ու ոնց ա կարելի ֆիքսել թե ինչ կառուցվածքով պատասխանի մեզ api-ը (մի քիչ էլ առնչվում ենք pydantic-ի հետ, որը հետո ենք անցնելու)։
Որպես կիրառություն սարքում ենք ծրագիր որը youtube-ի վիդեո ստանալով քաշում ա իրա տռանսրիպտը (արել էինք նախորդ դասին) ու գենեռացնում ա timestamp-եր (կարևոր թեմաները որ վարկյաններին են սկսվում)
📺 Տեսանյութեր
🏡 Տնային
Կրեատիվությունն ա միակ լիմիտը։ Մի աշխարհ բան ա կարելի անել OpenAI-ով (հայերենի համար ավելի լավ ա Claude-ով անել բայց), կարաք գլխից նաև Streamlit app սարքեք։
📚 Նյութը
OpenAI
First of all pip install openai
Creating API Key
- https://platform.openai.com/settings/organization/api-keys
- https://platform.openai.com/docs/overview
SET OPENAI_API_KEY=sk-...
or
SETX OPENAI_API_KEY "sk-..." # saves it permanentlyLinux/Mac:
export OPENAI_API_KEY="sk-..."With Python:
import os
os.environ["OPENAI_API_KEY"] = "sk-..."MAKE SURE TO ALWAYS KEEP YOUR API KEY SECRET! (REMOVE IT FROM YOUR CODE BEFORE SHARING IT)
Or better use python-dotenv package to load it from .env file, see this lecture for more details.
OpenAI API
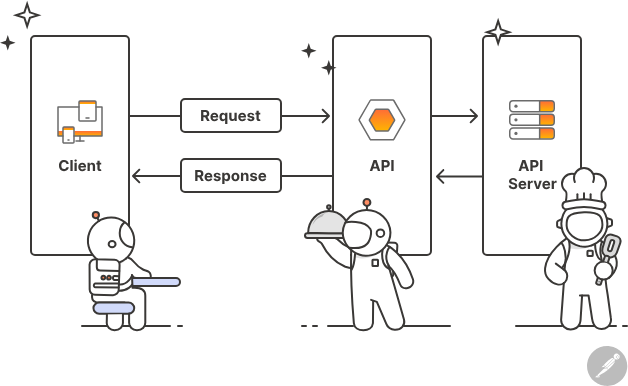
Regular Text Completion
!uv pip install dotenvUsing Python 3.11.13 environment at: c:\Users\hayk_\OneDrive\Desktop\01_python_math_ml_course\ma Resolved 2 packages in 475ms Prepared 1 package in 51ms Installed 2 packages in 234ms + dotenv==0.9.9 + python-dotenv==1.1.1
import os
from dotenv import load_dotenv
load_dotenv(override=True)
from openai import OpenAI
client = OpenAI(
# This is the default and can be omitted
api_key=os.getenv("OPENAI_API_KEY"),
)response = client.responses.create(
model="gpt-4o",
instructions="You are a professional youtube chapter and timestamp generator. I will provide you with a transcript of a video, and you will generate timestamps for the key points discussed in the video. The timestamps should be in the format 'HH:MM:SS' and should be accompanied by a brief description of the content at that timestamp.",
input="In this video, we will explore the fascinating world of quantum computing. We will start by discussing the basic principles of quantum mechanics and how they differ from classical physics. Then, we will delve into the concept of qubits and how they are used in quantum computers. We will also cover the challenges faced in building practical quantum computers and the potential applications of this technology in various fields such as cryptography, drug discovery, and artificial intelligence. Finally, we will look at some of the leading companies and research institutions working on quantum computing and their latest advancements.",
)
response#.output[0].content[0].textResponse(id='resp_03ab810b8afc3a420069747f9c1a1481a3b040c5a1d3e361e8', created_at=1769242524.0, error=None, incomplete_details=None, instructions="You are a professional youtube chapter and timestamp generator. I will provide you with a transcript of a video, and you will generate timestamps for the key points discussed in the video. The timestamps should be in the format 'HH:MM:SS' and should be accompanied by a brief description of the content at that timestamp.", metadata={}, model='gpt-4o-2024-08-06', object='response', output=[ResponseOutputMessage(id='msg_03ab810b8afc3a420069747f9d1c7481a3a9d0c4d51772dd9a', content=[ResponseOutputText(annotations=[], text='Certainly! Here are the suggested timestamps and chapter descriptions for the video:\n\n```\n00:00:00 - Introduction to Quantum Computing\n00:01:30 - Basic Principles of Quantum Mechanics vs. Classical Physics\n00:03:45 - Understanding Qubits in Quantum Computers\n00:06:15 - Challenges in Building Practical Quantum Computers\n00:08:40 - Potential Applications: Cryptography and Security\n00:10:20 - Quantum Computing in Drug Discovery\n00:11:45 - Impact on Artificial Intelligence\n00:13:15 - Leading Companies and Research Institutions\n00:15:00 - Latest Advancements in Quantum Computing\n```', type='output_text', logprobs=[])], role='assistant', status='completed', type='message')], parallel_tool_calls=True, temperature=1.0, tool_choice='auto', tools=[], top_p=1.0, background=False, conversation=None, max_output_tokens=None, max_tool_calls=None, previous_response_id=None, prompt=None, prompt_cache_key=None, reasoning=Reasoning(effort=None, generate_summary=None, summary=None), safety_identifier=None, service_tier='default', status='completed', text=ResponseTextConfig(format=ResponseFormatText(type='text'), verbosity='medium'), top_logprobs=0, truncation='disabled', usage=ResponseUsage(input_tokens=185, input_tokens_details=InputTokensDetails(cached_tokens=0), output_tokens=134, output_tokens_details=OutputTokensDetails(reasoning_tokens=0), total_tokens=319), user=None, billing={'payer': 'developer'}, completed_at=1769242527, frequency_penalty=0.0, presence_penalty=0.0, prompt_cache_retention=None, store=True)type(response)openai.types.responses.response.Responseresponse.output[0].content[0].text'Certainly! Here are the suggested timestamps and chapter descriptions for the video:\n\n```\n00:00:00 - Introduction to Quantum Computing\n00:01:30 - Basic Principles of Quantum Mechanics vs. Classical Physics\n00:03:45 - Understanding Qubits in Quantum Computers\n00:06:15 - Challenges in Building Practical Quantum Computers\n00:08:40 - Potential Applications: Cryptography and Security\n00:10:20 - Quantum Computing in Drug Discovery\n00:11:45 - Impact on Artificial Intelligence\n00:13:15 - Leading Companies and Research Institutions\n00:15:00 - Latest Advancements in Quantum Computing\n```'Image
from openai import OpenAI
import base64
client = OpenAI()
response = client.responses.create(
model="gpt-4.1-mini",
input="Generate a Ghibli style image of cheese",
tools=[{"type": "image_generation"}],
)
# Save the image to a file
image_data = [
output.result
for output in response.output
if output.type == "image_generation_call"
]
if image_data:
image_base64 = image_data[0]
with open("cheese.png", "wb") as f:
f.write(base64.b64decode(image_base64))--------------------------------------------------------------------------- PermissionDeniedError Traceback (most recent call last) Cell In[14], line 6 2 import base64 4 client = OpenAI() ----> 6 response = client.responses.create( 7 model="gpt-4.1-mini", 8 input="Generate a Ghibli style image of cheese", 9 tools=[{"type": "image_generation"}], 10 ) 12 # Save the image to a file 13 image_data = [ 14 output.result 15 for output in response.output 16 if output.type == "image_generation_call" 17 ] File c:\Users\hayk_\OneDrive\Desktop\01_python_math_ml_course\ma\Lib\site-packages\openai\resources\responses\responses.py:840, in Responses.create(self, background, conversation, include, input, instructions, max_output_tokens, max_tool_calls, metadata, model, parallel_tool_calls, previous_response_id, prompt, prompt_cache_key, reasoning, safety_identifier, service_tier, store, stream, stream_options, temperature, text, tool_choice, tools, top_logprobs, top_p, truncation, user, extra_headers, extra_query, extra_body, timeout) 803 def create( 804 self, 805 *, (...) 838 timeout: float | httpx.Timeout | None | NotGiven = not_given, 839 ) -> Response | Stream[ResponseStreamEvent]: --> 840 return self._post( 841 "/responses", 842 body=maybe_transform( 843 { 844 "background": background, 845 "conversation": conversation, 846 "include": include, 847 "input": input, 848 "instructions": instructions, 849 "max_output_tokens": max_output_tokens, 850 "max_tool_calls": max_tool_calls, 851 "metadata": metadata, 852 "model": model, 853 "parallel_tool_calls": parallel_tool_calls, 854 "previous_response_id": previous_response_id, 855 "prompt": prompt, 856 "prompt_cache_key": prompt_cache_key, 857 "reasoning": reasoning, 858 "safety_identifier": safety_identifier, 859 "service_tier": service_tier, 860 "store": store, 861 "stream": stream, 862 "stream_options": stream_options, 863 "temperature": temperature, 864 "text": text, 865 "tool_choice": tool_choice, 866 "tools": tools, 867 "top_logprobs": top_logprobs, 868 "top_p": top_p, 869 "truncation": truncation, 870 "user": user, 871 }, 872 response_create_params.ResponseCreateParamsStreaming 873 if stream 874 else response_create_params.ResponseCreateParamsNonStreaming, 875 ), 876 options=make_request_options( 877 extra_headers=extra_headers, extra_query=extra_query, extra_body=extra_body, timeout=timeout 878 ), 879 cast_to=Response, 880 stream=stream or False, 881 stream_cls=Stream[ResponseStreamEvent], 882 ) File c:\Users\hayk_\OneDrive\Desktop\01_python_math_ml_course\ma\Lib\site-packages\openai\_base_client.py:1259, in SyncAPIClient.post(self, path, cast_to, body, options, files, stream, stream_cls) 1245 def post( 1246 self, 1247 path: str, (...) 1254 stream_cls: type[_StreamT] | None = None, 1255 ) -> ResponseT | _StreamT: 1256 opts = FinalRequestOptions.construct( 1257 method="post", url=path, json_data=body, files=to_httpx_files(files), **options 1258 ) -> 1259 return cast(ResponseT, self.request(cast_to, opts, stream=stream, stream_cls=stream_cls)) File c:\Users\hayk_\OneDrive\Desktop\01_python_math_ml_course\ma\Lib\site-packages\openai\_base_client.py:1047, in SyncAPIClient.request(self, cast_to, options, stream, stream_cls) 1044 err.response.read() 1046 log.debug("Re-raising status error") -> 1047 raise self._make_status_error_from_response(err.response) from None 1049 break 1051 assert response is not None, "could not resolve response (should never happen)" PermissionDeniedError: Error code: 403 - {'error': {'message': 'Your organization must be verified to use the model `gpt-4.1-mini`. Please go to: https://platform.openai.com/settings/organization/general and click on Verify Organization. If you just verified, it can take up to 15 minutes for access to propagate.', 'type': 'invalid_request_error', 'param': None, 'code': None}}
result.data[0].b64_jsonresult.data[0]from openai import OpenAI
import base64
client = OpenAI()
prompt = """
Generate a Jibiri style image of cheese.
"""
result = client.images.generate(
model="dall-e-2",
prompt=prompt
)
image_base64 = result.data[0].b64_json
if image_base64 is None:
print(result.data[0].url)
# image_bytes = base64.b64decode(image_base64)
# # Save the image to a file
# with open("cheese.png", "wb") as f:
# f.write(image_bytes)https://oaidalleapiprodscus.blob.core.windows.net/private/org-ttpmtIE2I4svAF3GF4fDbAI6/user-ikPOmBgtK5dBqbZAFApYEkzD/img-uU9np2kVZ3ZdQ5z1ggJIoLoy.png?st=2026-01-24T07%3A18%3A52Z&se=2026-01-24T09%3A18%3A52Z&sp=r&sv=2024-08-04&sr=b&rscd=inline&rsct=image/png&skoid=9346e9b9-5d29-4d37-a0a9-c6f95f09f79d&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2026-01-24T07%3A30%3A18Z&ske=2026-01-25T07%3A30%3A18Z&sks=b&skv=2024-08-04&sig=Qypmj/ve9uAXKhJn6YV5md0LJPmzwJFlZD9fTWlfpTQ%3D# get image from url
import requests
response = requests.get(result.data[0].url)
# Save the image to a file
with open("cheese.png", "wb") as f:
f.write(response.content)Audio
import base64
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-audio-preview",
modalities=["text", "audio"],
audio={"voice": "alloy", "format": "wav"},
messages=[
{
"role": "user",
"content": "What is the best cheese in Armenia?"
}
]
)
# print(completion.choices[0])
wav_bytes = base64.b64decode(completion.choices[0].message.audio.data)
with open("cheese.wav", "wb") as f:
f.write(wav_bytes)Structured output
summary -
main_idea -
Transcription - [timestamp, text]
{
"summary": ...
"main_idea": ...,
}
["summary"]from pydantic import BaseModel
from openai import OpenAI
client = OpenAI()
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
messages_lst = [
{"role": "system", "content": "Extract the event information."},
{"role": "user", "content": "Alice and Bob are going to a science fair on Friday."},
]
completion = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=messages_lst,
response_format=CalendarEvent,
)
event = completion.choices[0].message.parsedevent.participants['Alice', 'Bob']History
messages_lst.append(
{
"role": "assistant",
"content": f"Event Name: {event.name}, Date: {event.date}, Participants: {', '.join(event.participants)}"
}
)
messages_lst.append(
{
"role": "user",
"content": f"Output the date in ISO format"
}
)messages_lst[{'role': 'system', 'content': 'Extract the event information.'},
{'role': 'user',
'content': 'Alice and Bob are going to a science fair on Friday.'},
{'role': 'assistant',
'content': 'Event Name: Science Fair, Date: 2023-10-13, Participants: Alice, Bob'},
{'role': 'user', 'content': 'Output the date in ISO format'}]completion = client.chat.completions.parse(
model="gpt-4o-2024-08-06",
messages=messages_lst,
response_format=CalendarEvent,
)
# event = completion.choices#[0].message.parsedcompletion.choices[0].message.parsedCalendarEvent(name='Science Fair', date='2023-10-13', participants=['Alice', 'Bob'])🛠️ Գործնական
Timestamp generator
from typing import List
from pytubefix import YouTube
from datetime import datetime
from dataclasses import dataclass@dataclass()
class VideoInfo:
video_id: str
title: str
keywords: List[str]
publish_date: str
length_seconds: int
@staticmethod
def get_days_since_publish(publish_date) -> int:
if isinstance(publish_date, datetime):
publish_date = publish_date.strftime("%Y-%m-%d")
publish_date = datetime.strptime(publish_date, "%Y-%m-%d")
current_date = datetime.now()
return (current_date - publish_date).days
def __post_init__(self):
if not isinstance(self.video_id, str):
raise ValueError("video_id must be a string")
if not isinstance(self.length_seconds, int):
raise ValueError("length_seconds must be an integer")
self.days_since_publish = self.get_days_since_publish(self.publish_date)class YouTubeVideo:
def __init__(self, url: str):
self.video = YouTube(url)
def get_metadata(self) -> VideoInfo:
return VideoInfo(
video_id=self.video.video_id,
title=self.video.title,
keywords=self.video.keywords,
publish_date=self.video.publish_date,
length_seconds=self.video.length
)
def get_transcript(self, language: str = "de", _format = "txt") -> str:
print(f"Fetching transcript for language: {language}")
print(f"Available languages: {self.video.captions.keys()}")
captions = self.video.captions.get(language)
if not captions:
raise ValueError(f"No captions available for language: {language}")
if _format == "txt":
self.text = captions.generate_txt_captions()
elif _format == "srt":
self.text = captions.generate_srt_captions()
else:
raise ValueError(f"Unsupported format: {_format}. Supported formats are 'txt' and 'srt'.")
return self.text
def download_transcript(self, language: str = "de", title: str = "transcript", output_path: str = "transcript.txt") -> None:
captions = self.video.captions.get(language)
if not captions:
raise ValueError(f"No captions available for language: {language}")
captions.download(title=title, output_path=output_path)
vid = YouTubeVideo("https://youtu.be/nU3fzO94lBw")
metadata = vid.get_metadata()transcript = vid.get_transcript(language="a.hy", _format="srt")Fetching transcript for language: a.hy
Available languages: KeysView({'a.hy': <Caption lang="Armenian (auto-generated)" code="a.hy">})response = client.responses.create(
model="gpt-4o",
instructions="You are a professional youtube chapter and timestamp generator. I will provide you with a transcript of a video, and you will generate timestamps for the key points discussed in the video. The timestamps should be in the format 'HH:MM:SS' and should be accompanied by a brief description of the content at that timestamp. The descriptions should be in the same language as the transcript.",
input=transcript,
)
response.output[0].content[0].text'00:00:00 - **Ծիրանների հաշվարկ**: Խոսք ծիրանների և խնձորների քանակի վրա: \n00:00:12 - **Խնձորների հաշվարկ**: Ուսումնասիրում ենք խնձորների թիվը: \n00:00:26 - **Համեմատություն**: Քննարկում ենք խնձորների և ծիրանների քանակի համեմատությունը: \n00:00:56 - **Մաթեմատիկական պատկերացում**: Ներդրվում է բնական թվերի բազմության գաղափարը: \n00:01:18 - **0-ից 1 միջակայքը**: Քննարկվում է 0-ից 1 թվերի միջակայքի գաղափարը: \n00:01:40 - **Համեմատական վերլուծություն**: Ուսումնասիրում ենք երկու հավաքածուների հզորությունները: \n00:02:43 - **Հավասարության գաղափար**: Հնարավորությունը n-ի և 0-1 միջակայքի հավասարության: \n00:04:00 - **Հահաքանակների օրինակ**: Նորից հայտարարերը, բայց այս անգամ ռուսերեն: \n00:05:40 - **Անվերջության քննարկում**: Ինչպես համեմատել երկու անվերջությունների: \n00:07:16 - **Անհամապատասխանություն**: Բացատրում, որ տարերի թվի հաշվարկն անհնար է 0-1 միջակայքի համար: \n00:11:04 - **Անվերջություն ավելի շատ է**: Հասկանում ենք, որ 0-1 միջակայքը պարունակում է ավելի շատ թվեր քան բնական թվերը: \n00:12:15 - **Եզրափակիչ խոսքեր**: Հրավիրում ենք դիտելու Գիլբերտի հյուրանոցի խնդիրը: \n\nՀիշեցում բոլոր կետերում ավելի մանրամասն քննարկումը տեսնել մեկնաբանություններում:'print(response.output[0].content[0].text)00:00:00 - **Ծիրանների հաշվարկ**: Խոսք ծիրանների և խնձորների քանակի վրա:
00:00:12 - **Խնձորների հաշվարկ**: Ուսումնասիրում ենք խնձորների թիվը:
00:00:26 - **Համեմատություն**: Քննարկում ենք խնձորների և ծիրանների քանակի համեմատությունը:
00:00:56 - **Մաթեմատիկական պատկերացում**: Ներդրվում է բնական թվերի բազմության գաղափարը:
00:01:18 - **0-ից 1 միջակայքը**: Քննարկվում է 0-ից 1 թվերի միջակայքի գաղափարը:
00:01:40 - **Համեմատական վերլուծություն**: Ուսումնասիրում ենք երկու հավաքածուների հզորությունները:
00:02:43 - **Հավասարության գաղափար**: Հնարավորությունը n-ի և 0-1 միջակայքի հավասարության:
00:04:00 - **Հահաքանակների օրինակ**: Նորից հայտարարերը, բայց այս անգամ ռուսերեն:
00:05:40 - **Անվերջության քննարկում**: Ինչպես համեմատել երկու անվերջությունների:
00:07:16 - **Անհամապատասխանություն**: Բացատրում, որ տարերի թվի հաշվարկն անհնար է 0-1 միջակայքի համար:
00:11:04 - **Անվերջություն ավելի շատ է**: Հասկանում ենք, որ 0-1 միջակայքը պարունակում է ավելի շատ թվեր քան բնական թվերը:
00:12:15 - **Եզրափակիչ խոսքեր**: Հրավիրում ենք դիտելու Գիլբերտի հյուրանոցի խնդիրը:
Հիշեցում բոլոր կետերում ավելի մանրամասն քննարկումը տեսնել մեկնաբանություններում:Streamlit - environment variable setup🎲 19 (01)
- ▶️Alex Yemenidjian (WCIT speech)
- 🎲Random link
- 🇦🇲🎶C-rouge (Արի’, իմ սոխակ)
- 🌐🎶Pink Floyd (Dark side of the moon)
- 🤌Կարգին
Նշում։ Floyd-ենք ոչ թե երգեր են գրել, այլ ալբոմներ, նենց որ անարդար չի ամբողջ ալբոմը դնելը :-)